
25. 实现 GPT 嵌入层#
25.1. 介绍#
上一节我们已成功构建了 GPT 模型的预训练数据集。本小节将开始实现 GPT 模型的核心组件。
在深入 GPT 模型内部细节之前,我们先实现数据进入模型之前的数据处理流水线。
25.2. 输入嵌入流水线#
在 GPT 等大型语言模型的前端处理中,输入文本的转换遵循一条精心设计的流水线,其核心目标是将离散的、非结构化的自然语言文本,转化为模型能够理解和处理的、富含语义与结构信息的连续数值表示。这条流水线是模型性能的基石,其设计直接关系到模型对语言顺序、上下文和语义的捕捉能力。
下图清晰地展示了这一处理流程的核心阶段:
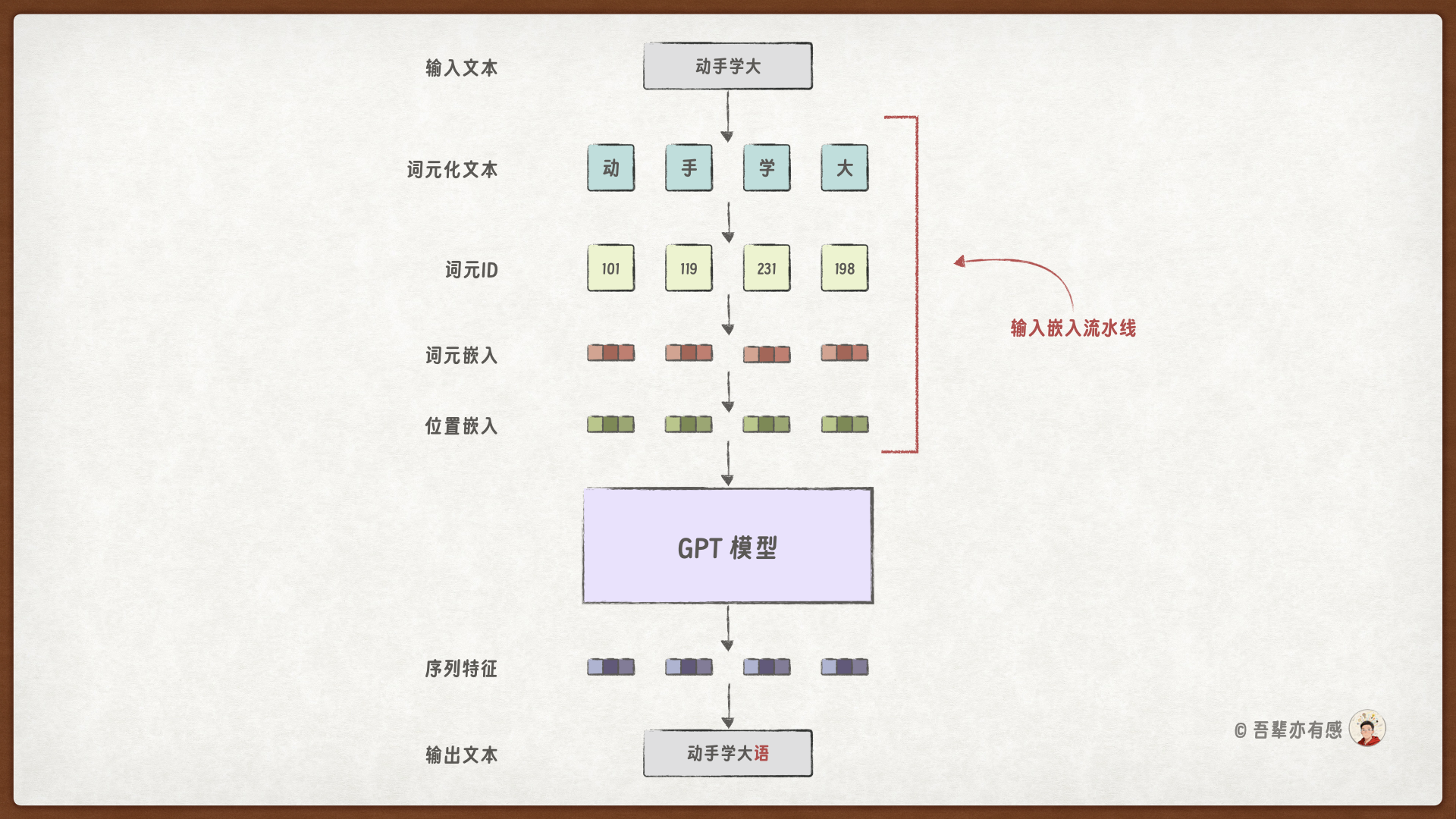
输入嵌入流水线整个处理流程可以分为三个关键阶段,最终输出的是融合了词义与位置信息的“输入嵌入”,作为 GPT 模型的输入。
25.2.1. 第一阶段:文本分词与词元化#
原始输入文本首先经过分词(Tokenization) 处理。这个过程类似于工厂流水线中将原材料切割为标准件。具体而言,通过基于规则(如正则表达式)或更先进的算法(如 BPE,字节对编码),将连续的文本字符串分割成一系列离散的、有意义的词元(Tokens)。这些词元可以是单词、子词甚至标点符号。同时,为了处理模型未见过的新词或标记文本边界,通常会引入特殊词元,如 <|unk|>(未知词)和 <|endoftext|>(文本结束)。此步骤的输出是一个词元序列,为后续的数值化映射做好了准备。
25.2.2. 第二阶段:词元到向量的映射#
得到词元序列后,流水线进入数值转换阶段。此阶段包含两个层,分别负责将词元映射为词元嵌入(Token Embedding)和位置嵌入(Positional Embedding)。这两个嵌入向量最终被相加,形成最终的输入嵌入(Input Embedding)。
词元嵌入(Token Embedding):这是流水线中的一个核心“工位”。每个词元通过查找词嵌入矩阵,被映射为一个固定长度的连续向量(例如 512 维或 768 维)。这个矩阵可视为一个巨大的“词典”,其中每个词条(词元 ID)对应一个向量。这些向量并非随机,而是在模型训练过程中学习得到的,能够编码丰富的语义信息——语义相近的词,其向量在空间中的距离也更近。此步骤解决了如何让基于数值计算的深度学习模型“理解”离散符号的问题。
位置嵌入(Positional Embedding):由于 Transformer 所使用自注意力机制本身不具备感知词元顺序的能力,必须额外注入位置信息。位置嵌入层为序列中的每一个位置(第 0 个,第 1 个,第 2 个……)生成一个唯一的、与词元嵌入维度相同的向量。这一设计确保了模型不仅能知道“词元是什么”,还能知道“词元出现在序列的哪个位置”,这对于理解语言逻辑至关重要。
25.2.3. 第三阶段:语义和位置信息的融合#
最后,来自词元嵌入层的语义向量与来自位置嵌入层的位置向量进行逐元素相加。这一操作完美融合了词元的语义信息与位置信息,生成了最终的输入嵌入(Input Embeddings)。
此前,我们已使用分词器完成了第一阶段的操作,接下来将实现嵌入流水线的其余部分。
25.3. 环境配置#
25.3.1. 安装依赖#
!pip install --upgrade dsxllm
25.3.2. 环境版本#
from dsxllm.util import show_version
show_version()
本书愿景:
+------+--------------------------------------------------------+
| Info | 《动手学大语言模型》 |
+------+--------------------------------------------------------+
| 作者 | 吾辈亦有感 |
| 哔站 | https://space.bilibili.com/3546632320715420 |
| 定位 | 基于'从零构建'的理念,用实战帮助程序员快速入门大模型。 |
| 愿景 | 若让你的AI学习之路走的更容易一点,我将倍感荣幸!祝好😄 |
+------+--------------------------------------------------------+
环境信息:
+-------------+--------------+------------------------+
| Python 版本 | PyTorch 版本 | PyTorch Lightning 版本 |
+-------------+--------------+------------------------+
| 3.12.12 | 2.10.0 | 2.6.1 |
+-------------+--------------+------------------------+
25.4. 词元嵌入层#
在自然语言处理任务中,词向量化(Word Embedding)是表示自然语言里单词的一种方法,即把每个词都表示为一个 N 维空间内的点,即一个高维空间内的向量。通过这种方法,实现把自然语言理解转换为向量计算。我们直接使用 PyTorch 提供的 torch.nn.Embedding 层来实现词元嵌入。
# 词元嵌入层
import torch
from torchinfo import summary
from dsxllm.util import print_red
# 词表大小
vocab_size = 8
# 嵌入向量维度
emb_dim = 5
# 创建词元嵌入层,将token ID映射到嵌入向量
tok_emb = torch.nn.Embedding(vocab_size, emb_dim)
# 创建虚拟输入数据 (token ID)
batch_size = 2 # 批量大小
seq_len = 4 # 序列长度
# 词元嵌入层的输入,形状为 (batch_size, seq_len),其中的值表示每个样本的每个词元的 ID
dummy_input_tok = torch.randint(0, vocab_size, [batch_size, seq_len])
print_red("词元嵌入层的输入:")
print(dummy_input_tok)
print()
print_red("词元嵌入层的详情:")
summary(
tok_emb,
input_data=dummy_input_tok,
col_names=("input_size", "output_size", "num_params"),
row_settings=("var_names",),
)
词元嵌入层的输入:
tensor([[1, 6, 4, 7],
[4, 6, 2, 6]])
词元嵌入层的详情:
===================================================================================================================
Layer (type (var_name)) Input Shape Output Shape Param #
===================================================================================================================
Embedding (Embedding) [2, 4] [2, 4, 5] 40
===================================================================================================================
Total params: 40
Trainable params: 40
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 0.00
===================================================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
===================================================================================================================
25.5. 位置嵌入层#
生成位置信息的两类方式:
位置编码:通过预定义的数学函数生成位置表示,最经典的实现来自原始 Transformer 论文中的正弦位置编码(Sinusoidal Position Encoding)。
位置嵌入:将位置信息视为可学习的参数,通过随机初始化并随模型训练逐步优化,类似于词嵌入(Word Embedding)。
在《动手学:Transformer》中我们实现了正弦位置编码(Sinusoidal Position Encoding),这里我们使用位置嵌入(Position Embedding)生成位置信息。
和词元嵌入一样,我们也直接使用 PyTorch 提供的 torch.nn.Embedding 层来实现位置嵌入,唯一的区别是位置嵌入的输入维度是最大序列长度(max_length),而词元嵌入的输入维度是词汇表大小(vocab_size)。
# 位置嵌入层
from torchinfo import summary
# 超参配置
max_length = 4
emb_dim = 5
# 创建位置嵌入层,将位置映射到嵌入向量
pos_emb = torch.nn.Embedding(max_length, emb_dim)
# 创建虚拟输入数据(位置 ID),位置嵌入层的输入:[1, context_Length]
dummy_input_pos = torch.arange(0, max_length)
print_red("位置嵌入层的输入:")
print(dummy_input_pos)
print()
print_red("位置嵌入层的详情:")
summary(
pos_emb,
input_data=dummy_input_pos,
col_names=("input_size", "output_size", "num_params"),
row_settings=("var_names",),
)
位置嵌入层的输入:
tensor([0, 1, 2, 3])
位置嵌入层的详情:
===================================================================================================================
Layer (type (var_name)) Input Shape Output Shape Param #
===================================================================================================================
Embedding (Embedding) [4] [4, 5] 20
===================================================================================================================
Total params: 20
Trainable params: 20
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 0.00
===================================================================================================================
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.00
===================================================================================================================
25.6. 为输入添加位置信息#
# 词表大小
from dsxllm.util import print_table
vocab_size = 8
# 嵌入向量维度
emb_dim = 5
seq_len = 4
batch_size = 2
# 随机生成输入 token ID 序列 (batch_size, seq_len)
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len))
# 创建词元嵌入层,将token ID映射到嵌入向量
token_embedding = torch.nn.Embedding(num_embeddings=vocab_size, embedding_dim=emb_dim)
# 创建位置嵌入层,将位置索引映射到嵌入向量
position_embedding = torch.nn.Embedding(num_embeddings=seq_len, embedding_dim=emb_dim)
# Token 嵌入,形状 (batch, seq_len, emb_dim)
token_embeds = token_embedding(input_ids)
# 生成位置索引 [0, 1, ..., seq_len-1])
position_ids = torch.arange(seq_len)
# 位置嵌入,形状 (seq_len, emb_dim)
position_embeds = position_embedding(position_ids)
# 输入嵌入 = 词元嵌入 + 位置嵌入,形状 (batch, seq_len, emb_dim)
input_embeds = token_embeds + position_embeds
print_table(
table_name="GPT 输入流水线数据变化",
field_names=["Name", "Data", "Shape", "Description"],
data=[
["原始输入", "input_ids", input_ids.shape, "[batch_size, seq_len]"],
["词元嵌入", "token_embeds", token_embeds.shape, "[batch_size, seq_len, emb_dim]"],
["位置嵌入", "position_embeds", position_embeds.shape, "[seq_len, emb_dim]"],
["最终输入", "input_embeds", input_embeds.shape, "[batch_size, seq_len, emb_dim]"],
],
)
GPT 输入流水线数据变化:
+----------+-----------------+-----------------------+--------------------------------+
| Name | Data | Shape | Description |
+----------+-----------------+-----------------------+--------------------------------+
| 原始输入 | input_ids | torch.Size([2, 4]) | [batch_size, seq_len] |
| 词元嵌入 | token_embeds | torch.Size([2, 4, 5]) | [batch_size, seq_len, emb_dim] |
| 位置嵌入 | position_embeds | torch.Size([4, 5]) | [seq_len, emb_dim] |
| 最终输入 | input_embeds | torch.Size([2, 4, 5]) | [batch_size, seq_len, emb_dim] |
+----------+-----------------+-----------------------+--------------------------------+
25.7. 答疑讨论#
○ 如果你觉得这篇文章有所帮助,欢迎将本文链接推荐给更多人——无论是分享到朋友圈、博客、社群,还是任何你常逛的地方。每一次转发,都会让它在搜索结果中更容易被有需要的人看到。